PinnedRule-based Reasoning in LLMs via Stepwise RefinementRemember learning to program? My teacher, and ardent disciple of Niklaus Wirth, taught us the principle of stepwise refinement as we worked…May 5, 2024May 5, 2024
PinnedDistilling DistillationQuestion: Is 2024 the year of slimming down LLMs into lithe and sprightly SLMs? SLM, of course stands for Small Language Model, and aptly…Feb 4, 2024Feb 4, 2024
PinnedSELF-INSTRUCT, the Low-cost LLM Alignment ProcessThis post is an easy-to-digest explanation of the seminal SELF-INSTRUCT paper that led to another influential work, Stanford Alpaca.May 8, 20231May 8, 20231
PinnedSpend Tokens to Make TokensThe old adage, you have to spend money to make money can bear fruit if you know what to spend it on. In the case of ChatGPT, you have to…Mar 20, 2023Mar 20, 2023
PinnedChatGPT’s Brush with DeceptionGandhi, the storied leader of India’s fight for freedom, logged his life experiments with truth and that inspired me to log ChatGPT’s…Dec 11, 2022Dec 11, 2022
Perplexity (the Metric) IlluminatedPerplexity, the metric, measures a language model’s ability to predict the next word in a sequence. Its a measure of how perplexed (or…Feb 11Feb 11
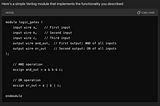
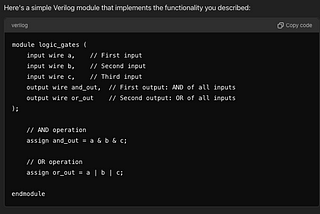
Experiments in Text-to-Verilog with ChatGPT-4oThis post logs my experiments with ChatGPT-4o with regards to taking logic expressed in natural language and translating it to Verilog…Aug 17, 2024Aug 17, 2024
“Where’s the Beef”, Codestral’s Fill-In-the-Middle MagicFill-in-the-Middle (FIM) is the ability of an LLM to generate the middle tokens sandwiched between (supplied) prefix and suffix tokens. To…Jun 4, 2024Jun 4, 2024